Claude Skills: Preserve Context with context:fork
Claude Code is a desktop application you download and run on your Mac or PC. Unlike the Claude website, which lives entirely in your browser, Claude Code is a real app with real access to your computer — specifically to the folders you choose to share with it. Think of it as giving Claude a pair of hands: with your permission, it can read files, write files, and work directly with documents sitting on your hard drive. This is what makes Skills possible. A Skill is a package of expertise you create — your company's coding standards, a security checklist, a writing style guide — stored as a structured instruction file that Claude can read when it needs to. The clever part is how Skills load. At the start of a session, Claude scans only the names and descriptions of your installed Skills, using just a handful of tokens for each one. Only when your prompt matches a Skill's description does Claude pull the full contents into the conversation's working memory.
This sounds efficient — and it is, at first. But as a session grows longer and prompts keep coming, the efficiency starts to break down. A prompt that resembles several Skills can trigger all of them, loading content that turns out to be only loosely relevant. And a Skill that gets triggered early in a conversation can be triggered again later by a similar prompt, loading the same content a second time into a context window that's already carrying the weight of everything that came before. That accumulation — redundant loads, broad matches, a growing pile of prior exchanges — is the context bloat problem that context: fork was designed to solve.
When you define a skill with the parameter context:fork, Claude runs that Skill in its own isolated workspace — like a side room — and only the clean result comes back to your main conversation. The verbose working output stays separate, your main context stays lean, and you pay only for what actually matters. For anyone doing serious work with multiple Skills across long sessions, context: fork is worth treating as a default, not an optional extra.
For those with CS backgrounds, think of Claude Code as a process that can spin up multiple threads, each thread with has its own focused task and working memory. All threads share the knowledge and context of the parent while working within their own memory store. The result is a cleaner context window and lower token costs.
What are the foundational skills needed for successful AI Coding
Organizing the course for CCA certification. what should people know as base knowledge to succeed in the course and pass the exam.
What about CS ? still important but not golden ticket to a job, what are the foundations for AI Coding - every major high level skill has its foundations,
foundations:
Piano : Hannon, Czerny exercises
BBall: go left and go right with the ball
Software (pre 2023) : cs fundamentals & data structures
AI Coding / Vibe Coding : .... here's what I seeCLI - command line basics+ cls,ls,cd,mkdir,…glob,grep
Python on the command line - versions matter, exec code
Virtual Environment Setups - uv is taking over venv and pip - know both
IDE: Focus on one: Codex, VS Code/Jetbrains IDEs + Claude Code
API Key management
Github / Git - the repo is the new resume
Ollama -use to load a local LLM; compare with frontier models
check out Anthropic’s Courses :
Anthropic Academy / Learn — Anthropic’s main learning hub, with Claude Code, API, and MCP learning paths and certificates.
Anthropic Courses (Skilljar) — the course catalog itself, including Claude 101, Claude Code 101, Claude Code in Action, Building with the Claude API, Introduction to Model Context Protocol, Model Context Protocol: Advanced Topics, Introduction to agent skills, and subagents.
Here’s what Perplexity says:
For a single student-facing recommendation, I’d pick Cursor as the default AI coding environment, with Claude Code used alongside it for CLI-based, agentic workflows. Cursor gives the broadest coverage across editing, chat, refactoring, multi-model support, and team-friendly IDE habits, while Claude Code adds the Anthropic-native CLI experience that maps well to CCA prep.pub.towardsai+2
Cursor is the easiest “one environment” answer because it is an IDE first, not just an assistant wrapper. That makes it better for students who need to learn code navigation, debugging, refactoring, and AI-assisted editing in one place.aubergine+1
one environment to recommend to students, say: use Cursor for daily development, and learn Claude Code as the CLI companion for CCA prep. That gives them the most transferable workflow: IDE skills, agentic CLI skills, and familiarity with Anthropic-specific tools.pub.towardsai+2
If the priority is maximizing alignment with CCA and Claude Code specifically, then VS Code + Claude Code is the more direct answer. It is less “magical” than Cursor, but it keeps the student closer to the core Anthropic workflow while still being broadly useful outside Anthropic.dev+1
the recommendation as: Cursor for the main environment, Claude Code for the Anthropic path.pub.towardsai+1
Neurons are not all alike
thoughts after reading McCulloch: Why the Mind is in the Head
current neuron networks assume uniformity across neurons which works for symmetric processing. what’s missing in the ai models are different computational units operating at different time scales. what we get, as Lorente de No says, a conception of the brain as an integrated whole. the role of chemicals adds to the complexity - cholinergic vs adrenergic with different effects. the prevalence of the chemicals that interact with the surfaces of the neurons and effect firing patterns where connected cells don’t carry the signal. so control may occur on the surface of the neuron supporting a huge number of chemical configurations. Also in attendance with McCulloch, deNo, - John von Neumann - memory not a place. often the memory comes to us - the memory size exceeds the capacity of the switching system where there are priorities - parts may get moved from less accessible to more accessible. seems like emotion can keep the memory in the ready to review section. resolving the emotion generating issue may reduce the memory as well as its emotional component.
RAG vs CAG: Understanding When to Use Each
There has been much discussion about whether CAG (Cache Augmented Generation) is replacing RAG (Retrieval Augmented Generation). The answer, as it often turns out, is: "It depends."
Quick Definitions
RAG (Retrieval Augmented Generation) fetches relevant chunks from an external knowledge base on every query, then conditions the language model on them. Think of it as a librarian who searches through the stacks each time you ask a question, pulling the most relevant books to help answer your query.
CAG (Cache Augmented Generation) preloads a large static corpus into a long-context LLM once, builds a KV cache of that context, and reuses it across many queries. This avoids repeated retrieval and recomputation. Imagine having all the relevant books already open on your desk, ready to reference instantly.
The Real Story: Complementary, Not Competitive
Despite the buzz suggesting CAG might replace RAG, the reality is more nuanced. These approaches address different challenges and often work best together. Here's when each shines:
Choose RAG when you need:
Dynamic, frequently changing knowledge (pricing, inventory, policies, real-time analytics)
Access to massive corpora that exceed practical context window limits
Vendor neutrality and the flexibility to swap LLM providers
Clear attribution trails for compliance and debugging
User-specific or multi-tenant data that can't be preloaded
Choose CAG when you have:
Relatively static knowledge bases that fit within context limits
High-query-volume workloads over the same corpus
Latency-sensitive applications where every millisecond counts
Simpler architectural requirements without separate retrieval infrastructure
FAQ systems, support playbooks, or internal documentation with stable content
The Hybrid Future
The most sophisticated systems are already combining both approaches. You might use CAG for your "always-on" background knowledge—product catalogs, base documentation, core policies—while layering RAG on top for fresh, dynamic, or user-specific data. This "RAG over CAG" pattern gives you the speed of caching with the flexibility of retrieval.
As context windows continue expanding and serving infrastructure improves, the design space will keep evolving. But one thing is clear: RAG isn't going anywhere. It's adapting, becoming more sophisticated with multi-modal retrieval, graph-aware search, and tighter integration with operational systems where CAG simply doesn't fit.
Bottom Line
If your knowledge is small, stable, and shared across users, bias toward CAG-first with minimal retrieval. If your knowledge is large, dynamic, or personalized, treat CAG as an optimization layer around a fundamentally RAG-like architecture, not a replacement for it.
Ready to dive deeper? Check out the audio discussion that explores these concepts in more detail.
2025 Reflections.. 2026 Next Steps
From Dendrites to Digital: A 2025 Retrospective and a Look Ahead
As 2025 comes to a close, I find myself in a mood of deep reflection. This year marked a massive transition in my life: I retired from Southern Methodist University (SMU) after 31 years of teaching Computer Science. Looking back, I am filled with gratitude for my great colleagues, but especially for my students. They often thanked me for the knowledge I shared, but I’m not sure they realized that they gave back to me far more than I gave to them. For me, teaching and explaining concepts has always been my ultimate pathway to learning.
The Berkeley Shift: From Theory to Pitch Decks Retirement, however, didn't mean slowing down. I transitioned to teaching Generative AI classes at Berkeley, and I have been thoroughly enjoying this new environment. The energy here is distinct, particularly the intense focus on the start-up ecosystem.
I’ve had to learn new tricks. Beyond the algorithms, I am now learning the ins and outs of helping students craft pitch decks and layout ideas for starting their own companies. It is invigorating to be surrounded by that builder’s mindset.
Needless to say, following AI developments has been a dominant theme of my 2025—not just to update my syllabi, but to use these models as personal assistants and associates. I treat the AI like a brilliant graduate student or a junior colleague; it is someone I can brainstorm with, bounce ideas off of, and use to sharpen my own thinking.
Full Circle: The Neuroscience Connection Perhaps the aspect of 2025 I am most excited about is a personal intellectual renaissance. The rise of neural networks has compelled me to revisit my early work in Atlanta at Emory in the late 60s and early 70s.
Back then, I was deep in the world of biology. I dissected human brains in my Neuroanatomy class alongside med students. In the lab, I performed neurophysiology experiments, recording brain activity with implanted electrodes in the thalamus and reticular formation. I was fascinated by the machinery of the mind.
However, that love affair was eclipsed the day a Digital Equipment PDP-8 appeared in our lab. I was immediately smitten. I switched my focus from wetware to hardware, heading over to Georgia Tech to understand how software and hardware could come together to build early AI systems.
Cajal and The Library Now that AI has captured the world's attention, I’ve been pulling out my dusty books. I found myself reflecting on a 1-1 seminar I had the great fortune to take with Professor Jerome Sutin at Emory. I recall being "scared stiff" meeting with him each week. To my surprise, he didn't direct me to the latest research on the Hypothalamus (his specialty). Instead, he assigned me the works of Lorente de Nó and Santiago Ramón y Cajal.
These weren't just dusty old papers. Santiago Ramón y Cajal, often called the father of modern neuroscience, was the first to rigorously document the neuron doctrine—the idea that the nervous system is made up of discrete individual cells rather than a continuous mesh. Using Golgi staining methods and his own incredible artistic talent, he mapped the intricate architecture of the brain's circuitry. Lorente de Nó, a student of Cajal, further advanced this by describing the columnar organization of the cortex, a concept that vaguely prefigures the layered architectures we see in deep learning today.
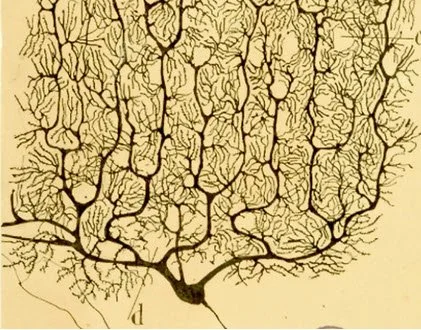
Santiago Ramón y Cajal’s Drawing of Pyramid Cells
This past year, wandering the wondrous stacks of the Berkeley Library, I tracked down a copy of The World of Ramón y Cajal. Seeing those drawings again took me right back to my days at Emory, bridging a 50-year gap between biological neurons and the artificial ones I teach today.
Advice for the AI Era: The Three Dimensions With AI making huge leaps in coding capabilities, many students—past and present—have asked me how to navigate their careers in this tumultuous atmosphere. My answer is to focus on three distinct dimensions:
1. Understand the Tech Ease up on the video games (I say this as someone who used to play Battlefield 2 for hours) and Netflix. Instead, digest everything 3Blue1Brown has to say about neural networks and transformers. Read the technical articles from Anthropic and Google. Use NotebookLM to organize and summarize.
But here is my "secret sauce" that I used heavily in 2025: Get a spiral notebook (one that you can bend back), a good pen (the Sarasa is my go-to implement), and WRITE and DRAW what you are learning. When you write by hand, you summarize. Your brain isn't just trying to hit the right keys; it is synthesizing reflections using "multi-modal input." Your visual system, your motor system, and your cortex are working to coordinate your transcriptions. That information and those images are being assimilated deep in your hippocampus in a way typing cannot replicate.
2. Understand the Players You need to know who is driving the ship. Understand the companies and the individuals vying for top dog status. Use YouTube to find interviews with the luminaries:
Andrej Karpathy (@karpathy): He produces detailed material and open teaching resources on building neural networks from scratch. He is essential for understanding modern deep learning systems.
Yann LeCun (@ylecun): The Chief AI Scientist at Meta. Follow him for cutting, often contrarian takes on representation learning and "world models."
Andrew Ng (@AndrewYNg): A perfect mix of pedagogy, MLOps, and applied LLM/vision. He remains one of the best high-signal "bridge" accounts moving from research to practice.
Lex Fridman (@lexfridman): His long-form conversations surface many of the above plus adjacent thinkers; it’s a great discovery mechanism for new people to follow.
3. Be Proactive and MAKE! In the 1990s, I had the good fortune to meet John Cage, the avant-garde composer and philosopher. I recently came across a quote attributed to him that I now incorporate in all my classes and advice to students:
"Nothing is a MISTAKE. There is no WIN. There is no LOSE. Only MAKE!"
Every week, design and implement a prototype project for yourself. Build a piece of software that might help you or someone else in their work. Use AI. Engage in "Vibe Coding"—see how well you can SPECIFY what you want the AI to build rather than just typing the syntax yourself. Try your hand with Agents.
As they say, "Just DO IT." Sure, you'll make mistakes and wander down blind alleys. But remember, learning what does NOT work is perhaps more valuable in the long run than getting it right the first time. And when you get stuck, remember you have a superstar at your disposal. Better Call Claude—or Gemini, or whomever. Prompt and you shall receive.
Looking Ahead to 2026 As I look toward 2026, the calendar is already filling up with exciting challenges:
I will continue developing specialized courses on AI and writing more articles.
I’m thrilled to start teaching an online GenAI class at the University of Bologna Business School in their "AI for Business" MS program.
On the social impact front, I will be teaching AI concepts in the Justice Through Code project through Columbia University. This program targets formerly incarcerated individuals, helping them restructure their lives through technology education.
A Request for You: As I map out my content for 2026, I want to know what you need. Fill out the form at : https://suggest-ai-video.streamlit.app
Let me know what topics, terms, or concepts you find confusing and I will try and address these in upcoming "Dr. C YouTube Shorts." If I pick your topic, I’ll be sure to give you a shout-out in the video!
2025 was a year of rediscovery and transition. I can’t wait to see what 2026 brings.
Where Does My AI Store Its Knowledge?
An ongoing question that confounds even the AI gurus: where exactly does a large language model store its knowledge? The reality is we don't know or understand how these systems do what they do.
What? But you AI guys wrote the program, right?
Yes – but:. The AI guys designed neural networks that were then used to TRAIN the neural network to learn to give correct answers. What nobody realized (experts included) was how effective this modeling of the human brain would to be.
So the fact that we have no clue about how AI stores information shouldn't surprise us. We don't have a clue how the human brain stores information either. We know that neurons communicate with each other—some neurons trigger the firing of other neurons, some inhibit firing. (Think about how learning a physical skill is very much learning what not to do). In artificial neural networks this biological dance has its equivalent in gradient descent, the algorithm which raises or lowers the weight of neuronal connections based on how well the model performs.
So, asking where ChatGPT "stores" its knowledge about Shakespeare is just like trying to pinpoint where the memory of your first bicycle ride lives. Can’t be done.
Consider this: if I ask you to describe your first bicycle ride, you don't retrieve a pre-written paragraph from some mental filing cabinet. Instead, you generate words on the fly from fragments—images, feelings, sensory memories—that come together to support your verbalization. When we converse with an AI, we read coherent sentences, but those sentences are the end product of a similar process: patterns distributed across millions of parameters interacting and coalescing into language. Both human memory and AI responses emerge from the dynamic interaction of countless connections, not from stored text waiting to be retrieved.
Is AI the end of Computer Science?
The rise of AI coding assistants like GitHub Copilot, Claude, and ChatGPT has sent ripples of anxiety through computer science departments and entry-level developers alike. These tools can generate functioning code from natural language descriptions, debug existing programs, and even explain complex algorithms in plain English. For many, the immediate question isn't whether AI will change programming—it's whether there will be any programming jobs left for humans, especially those just starting their careers.
This transformation raises profound questions for computer science students. Should they abandon their studies in favor of prompt engineering? Is learning data structures and algorithms still relevant when AI can implement them automatically? Are four years of computer science education becoming obsolete in the face of tools that seem to make programming accessible to anyone who can describe what they want in natural language?
The answer is emphatically no—computer science is not dead but still relevant. However, the simple focus on coding must evolve to emphasize the skills that become even more critical when working alongside AI coding assistants. These way to get an AI help you solve problems The fundamental ability to decompose complex problems into manageable components remains essential, perhaps more so than ever. When an AI generates code, someone still needs to understand whether that code solves the right problem and whether it does so efficiently and correctly.
Functional programming concepts become particularly valuable in an AI-augmented world. Understanding pure functions, immutability, and higher-order functions helps developers write code that's easier to test, debug, and reason about—qualities that become crucial when integrating AI-generated components. Similarly, object-oriented programming principles for defining classes and creating objects provide the architectural thinking needed to structure systems that incorporate AI-generated code into larger, maintainable applications.
Most critically, the ability to test AI-generated code through both white-box and black-box testing methodologies becomes a core competency. AI can write code, but it cannot guarantee that code is correct, secure, or optimal. Computer science students who understand testing frameworks, edge case identification, and verification techniques will find themselves more valuable than ever, serving as the quality assurance layer between AI output and production systems. The future belongs not to those who can code the fastest, but to those who can think the clearest about problems, architect robust solutions, and ensure that AI-generated code actually does what it's supposed to do.
Bottom Line: Don’t freak-out just because a bot can code. Understand your problem. Break it down and using your basic coding skills to understand and iterate to get the best out of the AI.